[Document(page_content='# Code understanding\n\nOverview\n\nLangChain is a useful tool designed to parse GitHub code repositories. By leveraging VectorStores, Conversational RetrieverChain, and GPT-4, it can answer questions in the context of an entire GitHub repository or generate new code. This documentation page outlines the essential components of the system and guides using LangChain for better code comprehension, contextual question answering, and code generation in GitHub repositories.\n\n## Conversational Retriever Chain\u200b\n\nConversational RetrieverChain is a retrieval-focused system that interacts with the data stored in a VectorStore. Utilizing advanced techniques, like context-aware filtering and ranking, it retrieves the most relevant code snippets and information for a given user query. Conversational RetrieverChain is engineered to deliver high-quality, pertinent results while considering conversation history and context.\n\nLangChain Workflow for Code Understanding and Generation\n\n1. Index the code base: Clone the target repository, load all files within, chunk the files, and execute the indexing process. Optionally, you can skip this step and use an already indexed dataset.\n\n\n\n2. Embedding and Code Store: Code snippets are embedded using a code-aware embedding model and stored in a VectorStore.\nQuery Understanding: GPT-4 processes user queries, grasping the context and extracting relevant details.\n\n\n\n3. Construct the Retriever: Conversational RetrieverChain searches the VectorStore to identify the most relevant code snippets for a given query.\n\n\n\n4. Build the Conversational Chain: Customize the retriever settings and define any user-defined filters as needed. \n\n\n\n5. Ask questions: Define a list of questions to ask about the codebase, and then use the ConversationalRetrievalChain to generate context-aware answers. The LLM (GPT-4) generates comprehensive, context-aware answers based on retrieved code snippets and conversation history.\n\n\n\nThe full tutorial is available below.\n\n- [Twitter the-algorithm codebase analysis with Deep Lake](/docs/use_cases/question_answering/how_to/code/twitter-the-algorithm-analysis-deeplake.html): A notebook walking through how to parse github source code and run queries conversation.\n\n- [LangChain codebase analysis with Deep Lake](/docs/use_cases/question_answering/how_to/code/code-analysis-deeplake.html): A notebook walking through how to analyze and do question answering over THIS code base.', metadata={'description': 'Overview', 'language': 'en', 'source': 'https://python.langchain.com/docs/use_cases/question_answering/how_to/code/', 'title': 'Code understanding | 🦜️🔗 Langchain'}),
Document(page_content='# Cookbook\n\nExample code for accomplishing common tasks with the LangChain Expression Language (LCEL). These examples show how to compose different Runnable (the core LCEL interface) components to achieve various tasks. If you\'re just getting acquainted with LCEL, the [Prompt + LLM](/docs/expression_language/cookbook/prompt_llm_parser) page is a good place to start.\n\n[📄️ Prompt + LLMThe most common and valuable composition is taking:](/docs/expression_language/cookbook/prompt_llm_parser)[📄️ RAGLet\'s look at adding in a retrieval step to a prompt and LLM, which adds up to a "retrieval-augmented generation" chain](/docs/expression_language/cookbook/retrieval)[📄️ Multiple chainsRunnables can easily be used to string together multiple Chains](/docs/expression_language/cookbook/multiple_chains)[📄️ Querying a SQL DBWe can replicate our SQLDatabaseChain with Runnables.](/docs/expression_language/cookbook/sql_db)[📄️ AgentsYou can pass a Runnable into an agent.](/docs/expression_language/cookbook/agent)[📄️ Code writingExample of how to use LCEL to write Python code.](/docs/expression_language/cookbook/code_writing)[📄️ Adding memoryThis shows how to add memory to an arbitrary chain. Right now, you can use the memory classes but need to hook it up manually](/docs/expression_language/cookbook/memory)[📄️ Adding moderationThis shows how to add in moderation (or other safeguards) around your LLM application.](/docs/expression_language/cookbook/moderation)[📄️ Using toolsYou can use any Tools with Runnables easily.](/docs/expression_language/cookbook/tools)', metadata={'description': "Example code for accomplishing common tasks with the LangChain Expression Language (LCEL). These examples show how to compose different Runnable (the core LCEL interface) components to achieve various tasks. If you're just getting acquainted with LCEL, the Prompt + LLM page is a good place to start.", 'language': 'en', 'source': 'https://python.langchain.com/docs/expression_language/cookbook/', 'title': 'Cookbook | 🦜️🔗 Langchain'}),
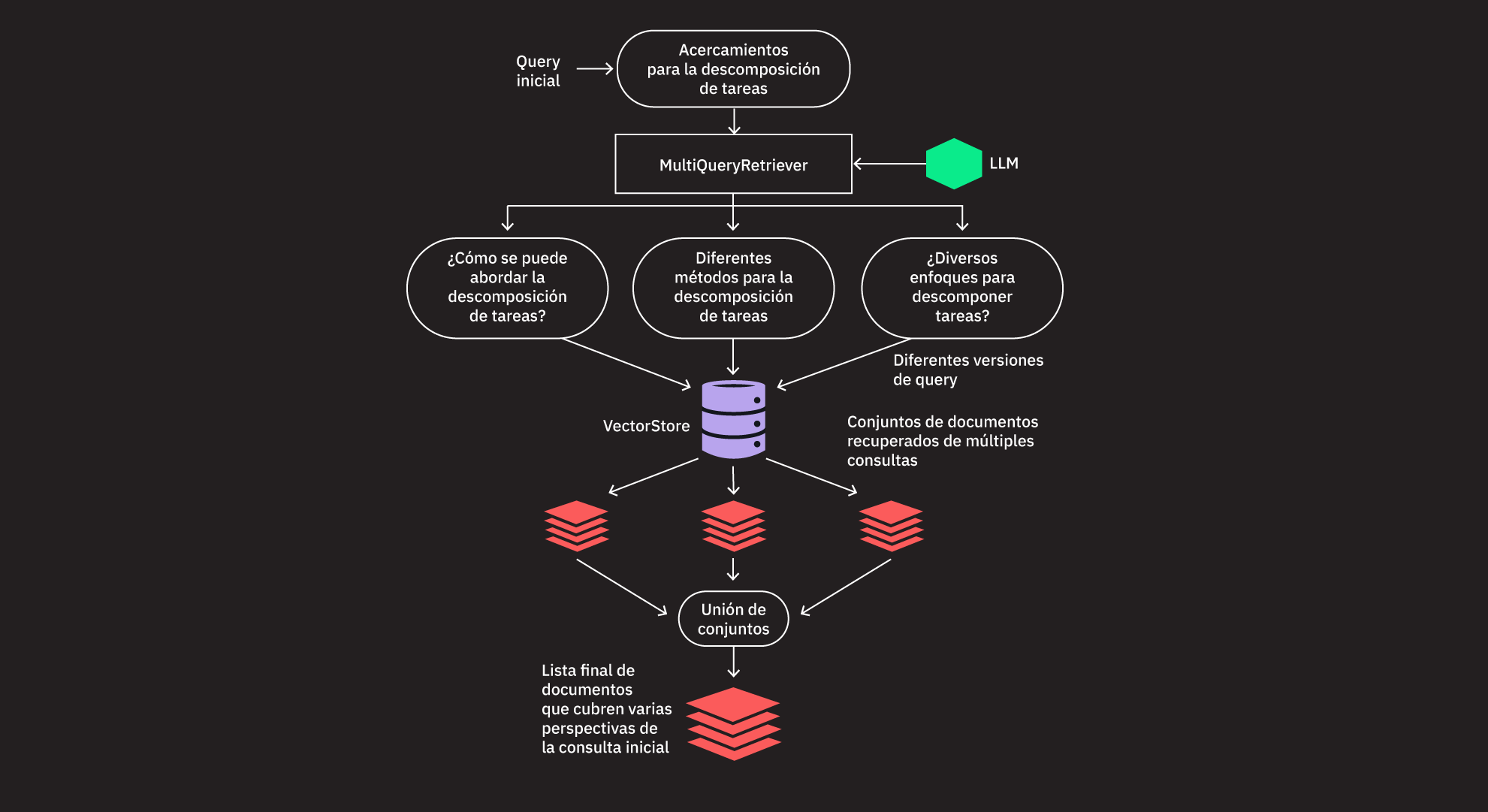
Document(page_content="# Retrieval\n\nMany LLM applications require user-specific data that is not part of the model's training set.\nThe primary way of accomplishing this is through Retrieval Augmented Generation (RAG).\nIn this process, external data is _retrieved_ and then passed to the LLM when doing the _generation_ step.\n\nLangChain provides all the building blocks for RAG applications - from simple to complex.\nThis section of the documentation covers everything related to the _retrieval_ step - e.g. the fetching of the data.\nAlthough this sounds simple, it can be subtly complex.\nThis encompasses several key modules.\n\n\n\n**Document loaders**\n\nLoad documents from many different sources.\nLangChain provides over 100 different document loaders as well as integrations with other major providers in the space,\nlike AirByte and Unstructured.\nWe provide integrations to load all types of documents (HTML, PDF, code) from all types of locations (private s3 buckets, public websites).\n\n**Document transformers**\n\nA key part of retrieval is fetching only the relevant parts of documents.\nThis involves several transformation steps in order to best prepare the documents for retrieval.\nOne of the primary ones here is splitting (or chunking) a large document into smaller chunks.\nLangChain provides several different algorithms for doing this, as well as logic optimized for specific document types (code, markdown, etc).\n\n**Text embedding models**\n\nAnother key part of retrieval has become creating embeddings for documents.\nEmbeddings capture the semantic meaning of the text, allowing you to quickly and\nefficiently find other pieces of text that are similar.\nLangChain provides integrations with over 25 different embedding providers and methods,\nfrom open-source to proprietary API,\nallowing you to choose the one best suited for your needs.\nLangChain provides a standard interface, allowing you to easily swap between models.\n\n**Vector stores**\n\nWith the rise of embeddings, there has emerged a need for databases to support efficient storage and searching of these embeddings.\nLangChain provides integrations with over 50 different vectorstores, from open-source local ones to cloud-hosted proprietary ones,\nallowing you to choose the one best suited for your needs.\nLangChain exposes a standard interface, allowing you to easily swap between vector stores.\n\n**Retrievers**\n\nOnce the data is in the database, you still need to retrieve it.\nLangChain supports many different retrieval algorithms and is one of the places where we add the most value.\nWe support basic methods that are easy to get started - namely simple semantic search.\nHowever, we have also added a collection of algorithms on top of this to increase performance.\nThese include:\n\n- [Parent Document Retriever](/docs/modules/data_connection/retrievers/parent_document_retriever): This allows you to create multiple embeddings per parent document, allowing you to look up smaller chunks but return larger context.\n\n- [Self Query Retriever](/docs/modules/data_connection/retrievers/self_query): User questions often contain a reference to something that isn't just semantic but rather expresses some logic that can best be represented as a metadata filter. Self-query allows you to parse out the _semantic_ part of a query from other _metadata filters_ present in the query.\n\n- [Ensemble Retriever](/docs/modules/data_connection/retrievers/ensemble): Sometimes you may want to retrieve documents from multiple different sources, or using multiple different algorithms. The ensemble retriever allows you to easily do this.\n\n- And more!", metadata={'description': "Many LLM applications require user-specific data that is not part of the model's training set.", 'language': 'en', 'source': 'https://python.langchain.com/docs/modules/data_connection/', 'title': 'Retrieval | 🦜️🔗 Langchain'}),
Document(page_content="[🗃️ Adapters1 items](/docs/guides/adapters/openai)[📄️ DebuggingIf you're building with LLMs, at some point something will break, and you'll need to debug. A model call will fail, or the model output will be misformatted, or there will be some nested model calls and it won't be clear where along the way an incorrect output was created.](/docs/guides/debugging)[🗃️ Deployment1 items](/docs/guides/deployments/)[🗃️ Evaluation4 items](/docs/guides/evaluation/)[📄️ FallbacksWhen working with language models, you may often encounter issues from the underlying APIs, whether these be rate limiting or downtime. Therefore, as you go to move your LLM applications into production it becomes more and more important to safe guard against these. That's why we've introduced the concept of fallbacks.](/docs/guides/fallbacks)[🗃️ LangSmith1 items](/docs/guides/langsmith/)[📄️ Run LLMs locallyUse case](/docs/guides/local_llms)[📄️ Model comparisonConstructing your language model application will likely involved choosing between many different options of prompts, models, and even chains to use. When doing so, you will want to compare these different options on different inputs in an easy, flexible, and intuitive way.](/docs/guides/model_laboratory)[🗃️ Privacy1 items](/docs/guides/privacy/presidio_data_anonymization/)[📄️ Pydantic compatibility- Pydantic v2 was released in June, 2023 (https://docs.pydantic.dev/2.0/blog/pydantic-v2-final/)](/docs/guides/pydantic_compatibility)[🗃️ Safety5 items](/docs/guides/safety/)", metadata={'description': 'Design guides for key parts of the development process', 'language': 'en', 'source': 'https://python.langchain.com/docs/guides', 'title': 'Guides | 🦜️🔗 Langchain'}),
Document(page_content='PubMedPubMed® by The National Center for Biotechnology Information, National Library of Medicine comprises more than 35 million citations for biomedical literature from MEDLINE, life science journals, and online books. Citations may include links to full text content from PubMed Central and publisher web sites.](/docs/integrations/retrievers/pubmed)[📄️ RePhraseQueryRetrieverSimple retriever that applies an LLM between the user input and the query pass the to retriever.](/docs/integrations/retrievers/re_phrase)[📄️ SEC filings dataSEC filings data powered by Kay.ai and Cybersyn.](/docs/integrations/retrievers/sec_filings)[📄️ SVMSupport vector machines (SVMs) are a set of supervised learning methods used for classification, regression and outliers detection.](/docs/integrations/retrievers/svm)[📄️ TF-IDFTF-IDF means term-frequency times inverse document-frequency.](/docs/integrations/retrievers/tf_idf)[📄️ VespaVespa is a fully featured search engine and vector database. It supports vector search (ANN), lexical search, and search in structured data, all in the same query.](/docs/integrations/retrievers/vespa)[📄️ Weaviate Hybrid SearchWeaviate is an open source vector database.](/docs/integrations/retrievers/weaviate-hybrid)[📄️ WikipediaWikipedia is a multilingual free online encyclopedia written and maintained by a community of volunteers, known as Wikipedians, through open collaboration and using a wiki-based editing system called MediaWiki. Wikipedia is the largest and most-read reference work in history.](/docs/integrations/retrievers/wikipedia)[📄️ ZepRetriever Example for Zep - A long-term memory store for LLM applications.](/docs/integrations/retrievers/zep_memorystore)', metadata={'language': 'en', 'source': 'https://python.langchain.com/docs/integrations/retrievers', 'title': 'Retrievers | 🦜️🔗 Langchain'}),
Document(page_content='#### API Reference:\n\n- [OpenAI](https://api.python.langchain.com/en/latest/llms/langchain.llms.openai.OpenAI.html)\n\n- [SelfQueryRetriever](https://api.python.langchain.com/en/latest/retrievers/langchain.retrievers.self_query.base.SelfQueryRetriever.html)\n\n- [AttributeInfo](https://api.python.langchain.com/en/latest/chains/langchain.chains.query_constructor.schema.AttributeInfo.html)\n\n## Testing it out\u200b\n\nAnd now we can try actually using our retriever!\n\n```python\n# This example only specifies a relevant query\nretriever.get_relevant_documents("What are some movies about dinosaurs")\n```\n\n```text\n query=\'dinosaur\' filter=None limit=None\n\n\n\n\n\n [Document(page_content=\'A bunch of scientists bring back dinosaurs and mayhem breaks loose\', metadata={\'year\': 1993, \'rating\': 7.7, \'genre\': \'science fiction\'}),\n Document(page_content=\'Toys come alive and have a blast doing so\', metadata={\'year\': 1995, \'genre\': \'animated\'}),\n Document(page_content=\'Leo DiCaprio gets lost in a dream within a dream within a dream within a ...\', metadata={\'year\': 2010, \'director\': \'Christopher Nolan\', \'rating\': 8.2}),\n Document(page_content=\'Three men walk into the Zone, three men walk out of the Zone\', metadata={\'year\': 1979, \'rating\': 9.9, \'director\': \'Andrei Tarkovsky\', \'genre\': \'science fiction\'})]\n```\n\n```python\n# This example only specifies a filter\nretriever.get_relevant_documents("I want to watch a movie rated higher than 8.5")\n```\n\n```text\n query=\' \' filter=Comparison(comparator=<Comparator.GT: \'gt\'>, attribute=\'rating\', value=8.5) limit=None\n\n\n\n\n\n [Document(page_content=\'Three men walk into the Zone, three men walk out of the Zone\', metadata={\'year\': 1979, \'rating\': 9.9, \'director\': \'Andrei Tarkovsky\', \'genre\': \'science fiction\'}),\n Document(page_content=\'A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea\', metadata={\'year\': 2006, \'director\': \'Satoshi Kon\', \'rating\': 8.6})]\n```\n\n```python\n# This example specifies a query and a filter\nretriever.get_relevant_documents("Has Greta Gerwig directed any movies about women")\n```\n\n```text\n query=\'women\' filter=Comparison(comparator=<Comparator.EQ: \'eq\'>, attribute=\'director\', value=\'Greta Gerwig\') limit=None\n\n\n\n\n\n [Document(page_content=\'A bunch of normal-sized women are supremely wholesome and some men pine after them\', metadata={\'year\': 2019, \'director\': \'Greta Gerwig\', \'rating\': 8.3})]\n```\n\n```python\n# This example specifies a composite filter\nretriever.get_relevant_documents("What\'s a highly rated (above 8.5) science fiction film?")\n```\n\n```text\n query=\' \' filter=Operation(operator=<Operator.AND: \'and\'>, arguments=[Comparison(comparator=<Comparator.GTE: \'gte\'>, attribute=\'rating\', value=8.5), Comparison(comparator=<Comparator.CONTAIN: \'contain\'>, attribute=\'genre\', value=\'science fiction\')]) limit=None\n\n\n\n\n\n [Document(page_content=\'Three men walk into the Zone, three men walk out of the Zone\', metadata={\'year\': 1979, \'rating\': 9.9, \'director\': \'Andrei Tarkovsky\', \'genre\': \'science fiction\'})]\n```\n\n## Filter k\u200b\n\nWe can also use the self query retriever to specify `k`: the number of documents to fetch.\n\nWe can do this by passing `enable_limit=True` to the constructor.\n\n```python\nretriever = SelfQueryRetriever.from_llm(\n llm,\n vectorstore,\n document_content_description,\n metadata_field_info,\n enable_limit=True,\n verbose=True,\n)\n```\n\n```python\n# This example only specifies a relevant query\nretriever.get_relevant_documents("what are two movies about dinosaurs")\n```\n\n```text\n query=\'dinosaur\' filter=None limit=2\n\n\n\n\n\n [Document(page_content=\'A bunch of scientists bring back dinosaurs and mayhem breaks loose\', metadata={\'year\': 1993, \'rating\': 7.7, \'genre\': \'science fiction\'}),\n Document(page_content=\'Toys come alive and have a blast doing so\', metadata={\'year\': 1995, \'genre\': \'animated\'})]\n```', metadata={'description': 'OpenSearch is a scalable, flexible, and extensible open-source software suite for search, analytics, and observability applications licensed under Apache 2.0. OpenSearch is a distributed search and analytics engine based on Apache Lucene.', 'language': 'en', 'source': 'https://python.langchain.com/docs/modules/data_connection/retrievers/self_query/opensearch_self_query', 'title': 'OpenSearch | 🦜️🔗 Langchain'}),
Document(page_content='```text\n Based on the given context, here is the answer to the question "What are the approaches to Task Decomposition?"\n \n There are three approaches to task decomposition:\n \n 1. LLM with simple prompting, such as "Steps for XYZ." or "What are the subgoals for achieving XYZ?"\n 2. Using task-specific instructions, like "Write a story outline" for writing a novel.', metadata={'description': 'Ollama allows you to run open-source large language models, such as LLaMA2, locally.', 'language': 'en', 'source': 'https://python.langchain.com/docs/integrations/chat/ollama', 'title': 'Ollama | 🦜️🔗 Langchain'})]