[Document(page_content='# MultiQueryRetriever\n\nDistance-based vector database retrieval embeds (represents) queries in high-dimensional space and finds similar embedded documents based on "distance". But, retrieval may produce different results with subtle changes in query wording or if the embeddings do not capture the semantics of the data well. Prompt engineering / tuning is sometimes done to manually address these problems, but can be tedious.\n\nThe `MultiQueryRetriever` automates the process of prompt tuning by using an LLM to generate multiple queries from different perspectives for a given user input query. For each query, it retrieves a set of relevant documents and takes the unique union across all queries to get a larger set of potentially relevant documents. By generating multiple perspectives on the same question, the `MultiQueryRetriever` might be able to overcome some of the limitations of the distance-based retrieval and get a richer set of results.\n\n```python\n# Build a sample vectorDB\nfrom langchain.vectorstores import Chroma\nfrom langchain.document_loaders import WebBaseLoader\nfrom langchain.embeddings.openai import OpenAIEmbeddings\nfrom langchain.text_splitter import RecursiveCharacterTextSplitter\n\n# Load blog post\nloader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")\ndata = loader.load()\n\n# Split\ntext_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)\nsplits = text_splitter.split_documents(data)\n\n# VectorDB\nembedding = OpenAIEmbeddings()\nvectordb = Chroma.from_documents(documents=splits, embedding=embedding)\n```\n\n> **API Reference:**\n> - [Chroma](https://api.python.langchain.com/en/latest/vectorstores/langchain.vectorstores.chroma.Chroma.html)\n> - [WebBaseLoader](https://api.python.langchain.com/en/latest/document_loaders/langchain.document_loaders.web_base.WebBaseLoader.html)\n> - [OpenAIEmbeddings](https://api.python.langchain.com/en/latest/embeddings/langchain.embeddings.openai.OpenAIEmbeddings.html)\n> - [RecursiveCharacterTextSplitter](https://api.python.langchain.com/en/latest/text_splitter/langchain.text_splitter.RecursiveCharacterTextSplitter.html)\n\n#### Simple usage\u200b\n\nSpecify the LLM to use for query generation, and the retriver will do the rest.\n\n```python\nfrom langchain.chat_models import ChatOpenAI\nfrom langchain.retrievers.multi_query import MultiQueryRetriever\n\nquestion = "What are the approaches to Task Decomposition?"\nllm = ChatOpenAI(temperature=0)\nretriever_from_llm = MultiQueryRetriever.from_llm(\n retriever=vectordb.as_retriever(), llm=llm\n)\n```\n\n> **API Reference:**\n> - [ChatOpenAI](https://api.python.langchain.com/en/latest/chat_models/langchain.chat_models.openai.ChatOpenAI.html)\n> - [MultiQueryRetriever](https://api.python.langchain.com/en/latest/retrievers/langchain.retrievers.multi_query.MultiQueryRetriever.html)\n\n```python\n# Set logging for the queries\nimport logging\n\nlogging.basicConfig()\nlogging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)\n```\n\n```python\nunique_docs = retriever_from_llm.get_relevant_documents(query=question)\nlen(unique_docs)\n```\n\n```text\n INFO:langchain.retrievers.multi_query:Generated queries: [\'1. How can Task Decomposition be approached?\', \'2. What are the different methods for Task Decomposition?\', \'3. What are the various approaches to decomposing tasks?\']\n\n 5\n```\n\n#### Supplying your own prompt\u200b\n\nYou can also supply a prompt along with an output parser to split the results into a list of queries.\n\n```python\nfrom typing import List\nfrom langchain.chains import LLMChain\nfrom pydantic import BaseModel, Field\nfrom langchain.prompts import PromptTemplate\nfrom langchain.output_parsers import PydanticOutputParser\n\n# Output parser will split the LLM result into a list of queries\nclass LineList(BaseModel):\n # "lines" is the key (attribute name) of the parsed output\n lines: List[str] = Field(description="Lines of text")\n\nclass LineListOutputParser(PydanticOutputParser):\n def __init__(self) -> None:\n super().__init__(pydantic_object=LineList)\n\n def parse(self, text: str) -> LineList:\n lines = text.strip().split("\\n")\n return LineList(lines=lines)\n\noutput_parser = LineListOutputParser()\n\nQUERY_PROMPT = PromptTemplate(\n input_variables=["question"],\n template="""You are an AI language model assistant. Your task is to generate five \n different versions of the given user question to retrieve relevant documents from a vector \n database. By generating multiple perspectives on the user question, your goal is to help\n the user overcome some of the limitations of the distance-based similarity search. \n Provide these alternative questions seperated by newlines.\n Original question: {question}""",\n)\nllm = ChatOpenAI(temperature=0)\n\n# Chain\nllm_chain = LLMChain(llm=llm, prompt=QUERY_PROMPT, output_parser=output_parser)\n\n# Other inputs\nquestion = "What are the approaches to Task Decomposition?"\n```\n\n> **API Reference:**\n> - [LLMChain](https://api.python.langchain.com/en/latest/chains/langchain.chains.llm.LLMChain.html)\n> - [PromptTemplate](https://api.python.langchain.com/en/latest/prompts/langchain.prompts.prompt.PromptTemplate.html)\n> - [PydanticOutputParser](https://api.python.langchain.com/en/latest/output_parsers/langchain.output_parsers.pydantic.PydanticOutputParser.html)\n\n```python\n# Run\nretriever = MultiQueryRetriever(\n retriever=vectordb.as_retriever(), llm_chain=llm_chain, parser_key="lines"\n) # "lines" is the key (attribute name) of the parsed output\n\n# Results\nunique_docs = retriever.get_relevant_documents(\n query="What does the course say about regression?"\n)\nlen(unique_docs)\n```\n\n```text\n INFO:langchain.retrievers.multi_query:Generated queries: ["1. What is the course\'s perspective on regression?", \'2. Can you provide information on regression as discussed in the course?\', \'3. How does the course cover the topic of regression?\', "4. What are the course\'s teachings on regression?", \'5. In relation to the course, what is mentioned about regression?\']\n\n 11\n```', metadata={'source': 'https://python.langchain.com/docs/modules/data_connection/retrievers/MultiQueryRetriever', 'title': 'MultiQueryRetriever | 🦜️🔗 Langchain', 'description': 'Distance-based vector database retrieval embeds (represents) queries in high-dimensional space and finds similar embedded documents based on "distance". But, retrieval may produce different results with subtle changes in query wording or if the embeddings do not capture the semantics of the data well. Prompt engineering / tuning is sometimes done to manually address these problems, but can be tedious.', 'language': 'en'}),
Document(page_content='# LOTR (Merger Retriever)\n\n`Lord of the Retrievers`, also known as `MergerRetriever`, takes a list of retrievers as input and merges the results of their get_relevant_documents() methods into a single list. The merged results will be a list of documents that are relevant to the query and that have been ranked by the different retrievers.\n\nThe `MergerRetriever` class can be used to improve the accuracy of document retrieval in a number of ways. First, it can combine the results of multiple retrievers, which can help to reduce the risk of bias in the results. Second, it can rank the results of the different retrievers, which can help to ensure that the most relevant documents are returned first.\n\n```python\nimport os\nimport chromadb\nfrom langchain.retrievers.merger_retriever import MergerRetriever\nfrom langchain.vectorstores import Chroma\nfrom langchain.embeddings import HuggingFaceEmbeddings\nfrom langchain.embeddings import OpenAIEmbeddings\nfrom langchain.document_transformers import (\n EmbeddingsRedundantFilter,\n EmbeddingsClusteringFilter,\n)\nfrom langchain.retrievers.document_compressors import DocumentCompressorPipeline\nfrom langchain.retrievers import ContextualCompressionRetriever\n\n# Get 3 diff embeddings.\nall_mini = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")\nmulti_qa_mini = HuggingFaceEmbeddings(model_name="multi-qa-MiniLM-L6-dot-v1")\nfilter_embeddings = OpenAIEmbeddings()\n\nABS_PATH = os.path.dirname(os.path.abspath(__file__))\nDB_DIR = os.path.join(ABS_PATH, "db")\n\n# Instantiate 2 diff cromadb indexs, each one with a diff embedding.\nclient_settings = chromadb.config.Settings(\n is_persistent=True,\n persist_directory=DB_DIR,\n anonymized_telemetry=False,\n)\ndb_all = Chroma(\n collection_name="project_store_all",\n persist_directory=DB_DIR,\n client_settings=client_settings,\n embedding_function=all_mini,\n)\ndb_multi_qa = Chroma(\n collection_name="project_store_multi",\n persist_directory=DB_DIR,\n client_settings=client_settings,\n embedding_function=multi_qa_mini,\n)\n\n# Define 2 diff retrievers with 2 diff embeddings and diff search type.\nretriever_all = db_all.as_retriever(\n search_type="similarity", search_kwargs={"k": 5, "include_metadata": True}\n)\nretriever_multi_qa = db_multi_qa.as_retriever(\n search_type="mmr", search_kwargs={"k": 5, "include_metadata": True}\n)\n\n# The Lord of the Retrievers will hold the ouput of boths retrievers and can be used as any other\n# retriever on different types of chains.\nlotr = MergerRetriever(retrievers=[retriever_all, retriever_multi_qa])\n```\n\n> **API Reference:**\n> - [MergerRetriever](https://api.python.langchain.com/en/latest/retrievers/langchain.retrievers.merger_retriever.MergerRetriever.html)\n> - [Chroma](https://api.python.langchain.com/en/latest/vectorstores/langchain.vectorstores.chroma.Chroma.html)\n> - [HuggingFaceEmbeddings](https://api.python.langchain.com/en/latest/embeddings/langchain.embeddings.huggingface.HuggingFaceEmbeddings.html)\n> - [OpenAIEmbeddings](https://api.python.langchain.com/en/latest/embeddings/langchain.embeddings.openai.OpenAIEmbeddings.html)\n> - [EmbeddingsRedundantFilter](https://api.python.langchain.com/en/latest/document_transformers/langchain.document_transformers.embeddings_redundant_filter.EmbeddingsRedundantFilter.html)\n> - [EmbeddingsClusteringFilter](https://api.python.langchain.com/en/latest/document_transformers/langchain.document_transformers.embeddings_redundant_filter.EmbeddingsClusteringFilter.html)\n> - [DocumentCompressorPipeline](https://api.python.langchain.com/en/latest/retrievers/langchain.retrievers.document_compressors.base.DocumentCompressorPipeline.html)\n> - [ContextualCompressionRetriever](https://api.python.langchain.com/en/latest/retrievers/langchain.retrievers.contextual_compression.ContextualCompressionRetriever.html)\n\n## Remove redundant results from the merged retrievers.\u200b\n\n```python\n# We can remove redundant results from both retrievers using yet another embedding.\n# Using multiples embeddings in diff steps could help reduce biases.\nfilter = EmbeddingsRedundantFilter(embeddings=filter_embeddings)\npipeline = DocumentCompressorPipeline(transformers=[filter])\ncompression_retriever = ContextualCompressionRetriever(\n base_compressor=pipeline, base_retriever=lotr\n)\n```\n\n## Pick a representative sample of documents from the merged retrievers.\u200b\n\n```python\n# This filter will divide the documents vectors into clusters or "centers" of meaning.\n# Then it will pick the closest document to that center for the final results.\n# By default the result document will be ordered/grouped by clusters.\nfilter_ordered_cluster = EmbeddingsClusteringFilter(\n embeddings=filter_embeddings,\n num_clusters=10,\n num_closest=1,\n)\n\n# If you want the final document to be ordered by the original retriever scores\n# you need to add the "sorted" parameter.\nfilter_ordered_by_retriever = EmbeddingsClusteringFilter(\n embeddings=filter_embeddings,\n num_clusters=10,\n num_closest=1,\n sorted=True,\n)\n\npipeline = DocumentCompressorPipeline(transformers=[filter_ordered_by_retriever])\ncompression_retriever = ContextualCompressionRetriever(\n base_compressor=pipeline, base_retriever=lotr\n)\n```\n\n## Re-order results to avoid performance degradation.\u200b\n\nNo matter the architecture of your model, there is a sustancial performance degradation when you include 10+ retrieved documents.\nIn brief: When models must access relevant information in the middle of long contexts, then tend to ignore the provided documents.\nSee: [https://arxiv.org/abs//2307.03172](https://arxiv.org/abs//2307.03172)\n\n```python\n# You can use an additional document transformer to reorder documents after removing redudance.\nfrom langchain.document_transformers import LongContextReorder\n\nfilter = EmbeddingsRedundantFilter(embeddings=filter_embeddings)\nreordering = LongContextReorder()\npipeline = DocumentCompressorPipeline(transformers=[filter, reordering])\ncompression_retriever_reordered = ContextualCompressionRetriever(\n base_compressor=pipeline, base_retriever=lotr\n)\n```\n\n> **API Reference:**\n> - [LongContextReorder](https://api.python.langchain.com/en/latest/document_transformers/langchain.document_transformers.long_context_reorder.LongContextReorder.html)', metadata={'source': 'https://python.langchain.com/docs/integrations/retrievers/merger_retriever', 'title': 'LOTR (Merger Retriever) | 🦜️🔗 Langchain', 'description': 'Lord of the Retrievers, also known as MergerRetriever, takes a list of retrievers as input and merges the results of their getrelevantdocuments() methods into a single list. The merged results will be a list of documents that are relevant to the query and that have been ranked by the different retrievers.', 'language': 'en'}),
Document(page_content='# Question Answering\n\n[](https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/extras/use_cases/question_answering/qa.ipynb)\n\n## Use case\u200b\n\nSuppose you have some text documents (PDF, blog, Notion pages, etc.) and want to ask questions related to the contents of those documents. LLMs, given their proficiency in understanding text, are a great tool for this.\n\nIn this walkthrough we\'ll go over how to build a question-answering over documents application using LLMs. Two very related use cases which we cover elsewhere are:\n\n- [QA over structured data](/docs/use_cases/qa_structured/sql) (e.g., SQL)\n- [QA over code](/docs/use_cases/code_understanding) (e.g., Python)\n\n\n\n## Overview\u200b\n\nThe pipeline for converting raw unstructured data into a QA chain looks like this:\n\n1. `Loading`: First we need to load our data. Unstructured data can be loaded from many sources. Use the [LangChain integration hub](https://integrations.langchain.com/) to browse the full set of loaders.\nEach loader returns data as a LangChain [Document](/docs/components/schema/document).\n\n2. `Splitting`: [Text splitters](/docs/modules/data_connection/document_transformers/) break `Documents` into splits of specified size\n\n3. `Storage`: Storage (e.g., often a [vectorstore](/docs/modules/data_connection/vectorstores/)) will house [and often embed](https://www.pinecone.io/learn/vector-embeddings/) the splits\n\n4. `Retrieval`: The app retrieves splits from storage (e.g., often [with similar embeddings](https://www.pinecone.io/learn/k-nearest-neighbor/) to the input question)\n\n5. `Generation`: An [LLM](/docs/modules/model_io/models/llms/) produces an answer using a prompt that includes the question and the retrieved data\n\n6. `Conversation` (Extension): Hold a multi-turn conversation by adding [Memory](/docs/modules/memory/) to your QA chain.\n\n\n\n## Quickstart\u200b\n\nTo give you a sneak preview, the above pipeline can be all be wrapped in a single object: `VectorstoreIndexCreator`. Suppose we want a QA app over this [blog post](https://lilianweng.github.io/posts/2023-06-23-agent/). We can create this in a few lines of code. First set environment variables and install packages:\n\n```python\npip install openai chromadb\n\n# Set env var OPENAI_API_KEY or load from a .env file\n# import dotenv\n\n# dotenv.load_dotenv()\n```\n\n```python\nfrom langchain.document_loaders import WebBaseLoader\nfrom langchain.indexes import VectorstoreIndexCreator\n\nloader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")\nindex = VectorstoreIndexCreator().from_loaders([loader])\n```\n\n> **API Reference:**\n> - [WebBaseLoader](https://api.python.langchain.com/en/latest/document_loaders/langchain.document_loaders.web_base.WebBaseLoader.html)\n> - [VectorstoreIndexCreator](https://api.python.langchain.com/en/latest/indexes/langchain.indexes.vectorstore.VectorstoreIndexCreator.html)\n\n```python\nindex.query("What is Task Decomposition?")\n```\n\n```text\n \' Task decomposition is a technique used to break down complex tasks into smaller and simpler steps. It can be done using LLM with simple prompting, task-specific instructions, or with human inputs. Tree of Thoughts (Yao et al. 2023) is an extension of Chain of Thought (Wei et al. 2022) which explores multiple reasoning possibilities at each step.\'\n```\n\nOk, but what\'s going on under the hood, and how could we customize this for our specific use case? For that, let\'s take a look at how we can construct this pipeline piece by piece.\n\n## Step 1. Load\u200b\n\nSpecify a `DocumentLoader` to load in your unstructured data as `Documents`. A `Document` is a piece of text (the `page_content`) and associated metadata.\n\n```python\nfrom langchain.document_loaders import WebBaseLoader\n\nloader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")\ndata = loader.load()\n```\n\n> **API Reference:**\n> - [WebBaseLoader](https://api.python.langchain.com/en/latest/document_loaders/langchain.document_loaders.web_base.WebBaseLoader.html)\n\n### Go deeper\u200b\n\n- Browse the > 120 data loader integrations [here](https://integrations.langchain.com/).\n- See further documentation on loaders [here](/docs/modules/data_connection/document_loaders/).\n\n## Step 2. Split\u200b\n\nSplit the `Document` into chunks for embedding and vector storage.\n\n```python\nfrom langchain.text_splitter import RecursiveCharacterTextSplitter\n\ntext_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)\nall_splits = text_splitter.split_documents(data)\n```\n\n> **API Reference:**\n> - [RecursiveCharacterTextSplitter](https://api.python.langchain.com/en/latest/text_splitter/langchain.text_splitter.RecursiveCharacterTextSplitter.html)\n\n### Go deeper\u200b\n\n- `DocumentSplitters` are just one type of the more generic `DocumentTransformers`, which can all be useful in this preprocessing step.\n- See further documentation on transformers [here](/docs/modules/data_connection/document_transformers/).\n- `Context-aware splitters` keep the location ("context") of each split in the original `Document`:- [Markdown files](/docs/use_cases/question_answering/how_to/document-context-aware-QA)\n- [Code (py or js)](/docs/use_cases/question_answering/docs/integrations/document_loaders/source_code)\n- [Documents](/docs/integrations/document_loaders/grobid)\n\n## Step 3. Store\u200b\n\nTo be able to look up our document splits, we first need to store them where we can later look them up.\nThe most common way to do this is to embed the contents of each document then store the embedding and document in a vector store, with the embedding being used to index the document.\n\n```python\nfrom langchain.embeddings import OpenAIEmbeddings\nfrom langchain.vectorstores import Chroma\n\nvectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())\n```\n\n> **API Reference:**\n> - [OpenAIEmbeddings](https://api.python.langchain.com/en/latest/embeddings/langchain.embeddings.openai.OpenAIEmbeddings.html)\n> - [Chroma](https://api.python.langchain.com/en/latest/vectorstores/langchain.vectorstores.chroma.Chroma.html)\n\n### Go deeper\u200b\n\n- Browse the > 40 vectorstores integrations [here](https://integrations.langchain.com/).\n\n- See further documentation on vectorstores [here](/docs/modules/data_connection/vectorstores/).\n\n- Browse the > 30 text embedding integrations [here](https://integrations.langchain.com/).\n\n- See further documentation on embedding models [here](/docs/modules/data_connection/text_embedding/).\n\nHere are Steps 1-3:\n\n\n\n## Step 4. Retrieve\u200b\n\nRetrieve relevant splits for any question using [similarity search](https://www.pinecone.io/learn/what-is-similarity-search/).\n\n```python\nquestion = "What are the approaches to Task Decomposition?"\ndocs = vectorstore.similarity_search(question)\nlen(docs)\n```\n\n```text\n 4\n```\n\n### Go deeper\u200b\n\nVectorstores are commonly used for retrieval, but they are not the only option. For example, SVMs (see thread [here](https://twitter.com/karpathy/status/1647025230546886658?s=20)) can also be used.\n\nLangChain [has many retrievers](/docs/modules/data_connection/retrievers/) including, but not limited to, vectorstores. All retrievers implement a common method `get_relevant_documents()` (and its asynchronous variant `aget_relevant_documents()`).\n\n```python\nfrom langchain.retrievers import SVMRetriever\n\nsvm_retriever = SVMRetriever.from_documents(all_splits,OpenAIEmbeddings())\ndocs_svm=svm_retriever.get_relevant_documents(question)\nlen(docs_svm)\n```\n\n> **API Reference:**\n> - [SVMRetriever](https://api.python.langchain.com/en/latest/retrievers/langchain.retrievers.svm.SVMRetriever.html)\n\n```text\n 4\n```\n\nSome common ways to improve on vector similarity search include:\n\n- `MultiQueryRetriever` [generates variants of the input question](/docs/modules/data_connection/retrievers/MultiQueryRetriever) to improve retrieval.\n- `Max marginal relevance` selects for [relevance and diversity](https://www.cs.cmu.edu/~jgc/publication/The_Use_MMR_Diversity_Based_LTMIR_1998.pdf) among the retrieved documents.\n- Documents can be filtered during retrieval using [metadata filters](/docs/use_cases/question_answering/how_to/document-context-aware-QA).\n\n```python\nimport logging\n\nfrom langchain.chat_models import ChatOpenAI\nfrom langchain.retrievers.multi_query import MultiQueryRetriever\n\nlogging.basicConfig()\nlogging.getLogger(\'langchain.retrievers.multi_query\').setLevel(logging.INFO)\n\nretriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(),\n llm=ChatOpenAI(temperature=0))\nunique_docs = retriever_from_llm.get_relevant_documents(query=question)\nlen(unique_docs)\n```\n\n> **API Reference:**\n> - [ChatOpenAI](https://api.python.langchain.com/en/latest/chat_models/langchain.chat_models.openai.ChatOpenAI.html)\n> - [MultiQueryRetriever](https://api.python.langchain.com/en/latest/retrievers/langchain.retrievers.multi_query.MultiQueryRetriever.html)\n\n## Step 5. Generate\u200b\n\nDistill the retrieved documents into an answer using an LLM/Chat model (e.g., `gpt-3.5-turbo`) with `RetrievalQA` chain.\n\n```python\nfrom langchain.chains import RetrievalQA\nfrom langchain.chat_models import ChatOpenAI\n\nllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)\nqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever())\nqa_chain({"query": question})\n```\n\n> **API Reference:**\n> - [RetrievalQA](https://api.python.langchain.com/en/latest/chains/langchain.chains.retrieval_qa.base.RetrievalQA.html)\n> - [ChatOpenAI](https://api.python.langchain.com/en/latest/chat_models/langchain.chat_models.openai.ChatOpenAI.html)\n\n```text\n {\'query\': \'What are the approaches to Task Decomposition?\',\n \'result\': \'The approaches to task decomposition include:\\n\\n1. Simple prompting: This approach involves using simple prompts or questions to guide the agent in breaking down a task into smaller subgoals. For example, the agent can be prompted with "Steps for XYZ" or "What are the subgoals for achieving XYZ?" to facilitate task decomposition.\\n\\n2. Task-specific instructions: In this approach, task-specific instructions are provided to the agent to guide the decomposition process. For example, if the task is to write a novel, the agent can be instructed to "Write a story outline" as a step in the task decomposition.\\n\\n3. Human inputs: This approach involves incorporating human inputs in the task decomposition process. Humans can provide guidance, feedback, and assistance to the agent in breaking down complex tasks into manageable subgoals.\\n\\nThese approaches aim to enable efficient handling of complex tasks by breaking them down into smaller, more manageable subgoals.\'}\n```\n\nNote, you can pass in an `LLM` or a `ChatModel` (like we did here) to the `RetrievalQA` chain.\n\n### Go deeper\u200b\n\n#### Choosing LLMs\u200b\n\n- Browse the > 55 LLM and chat model integrations [here](https://integrations.langchain.com/).\n- See further documentation on LLMs and chat models [here](/docs/modules/model_io/models/).\n- See a guide on local LLMS [here](/docs/modules/use_cases/question_answering/how_to/local_retrieval_qa).\n\n#### Customizing the prompt\u200b\n\nThe prompt in `RetrievalQA` chain can be easily customized.\n\n```python\nfrom langchain.chains import RetrievalQA\nfrom langchain.prompts import PromptTemplate\n\ntemplate = """Use the following pieces of context to answer the question at the end. \nIf you don\'t know the answer, just say that you don\'t know, don\'t try to make up an answer. \nUse three sentences maximum and keep the answer as concise as possible. \nAlways say "thanks for asking!" at the end of the answer. \n{context}\nQuestion: {question}\nHelpful Answer:"""\nQA_CHAIN_PROMPT = PromptTemplate.from_template(template)\n\nllm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)\nqa_chain = RetrievalQA.from_chain_type(\n llm,\n retriever=vectorstore.as_retriever(),\n chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}\n)\nresult = qa_chain({"query": question})\nresult["result"]\n```\n\n> **API Reference:**\n> - [RetrievalQA](https://api.python.langchain.com/en/latest/chains/langchain.chains.retrieval_qa.base.RetrievalQA.html)\n> - [PromptTemplate](https://api.python.langchain.com/en/latest/prompts/langchain.prompts.prompt.PromptTemplate.html)\n\n```text\n \'The approaches to Task Decomposition are (1) using simple prompting by LLM, (2) using task-specific instructions, and (3) incorporating human inputs. Thanks for asking!\'\n```\n\nWe can also store and fetch prompts from the LangChain prompt hub.\n\nThis will work with your [LangSmith API key](https://docs.smith.langchain.com/).\n\nFor example, see [here](https://smith.langchain.com/hub/rlm/rag-prompt) is a common prompt for RAG.\n\nWe can load this.\n\n```python\npip install langchainhub\n```\n\n```python\n# RAG prompt\nfrom langchain import hub\nQA_CHAIN_PROMPT_HUB = hub.pull("rlm/rag-prompt")\n\nqa_chain = RetrievalQA.from_chain_type(\n llm,\n retriever=vectorstore.as_retriever(),\n chain_type_kwargs={"prompt": QA_CHAIN_PROMPT_HUB}\n)\nresult = qa_chain({"query": question})\nresult["result"]\n```\n\n```text\n \'The approaches to task decomposition include using LLM with simple prompting, task-specific instructions, and human inputs.\'\n```\n\n#### Return source documents\u200b\n\nThe full set of retrieved documents used for answer distillation can be returned using `return_source_documents=True`.\n\n```python\nfrom langchain.chains import RetrievalQA\n\nqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever(),\n return_source_documents=True)\nresult = qa_chain({"query": question})\nprint(len(result[\'source_documents\']))\nresult[\'source_documents\'][0]\n```\n\n> **API Reference:**\n> - [RetrievalQA](https://api.python.langchain.com/en/latest/chains/langchain.chains.retrieval_qa.base.RetrievalQA.html)\n\n```text\n 4\n\n Document(page_content=\'Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.\', metadata={\'description\': \'Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.\\nAgent System Overview In a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:\', \'language\': \'en\', \'source\': \'https://lilianweng.github.io/posts/2023-06-23-agent/\', \'title\': "LLM Powered Autonomous Agents | Lil\'Log"})\n```\n\n#### Return citations\u200b\n\nAnswer citations can be returned using `RetrievalQAWithSourcesChain`.\n\n```python\nfrom langchain.chains import RetrievalQAWithSourcesChain\n\nqa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm,retriever=vectorstore.as_retriever())\n\nresult = qa_chain({"question": question})\nresult\n```\n\n> **API Reference:**\n> - [RetrievalQAWithSourcesChain](https://api.python.langchain.com/en/latest/chains/langchain.chains.qa_with_sources.retrieval.RetrievalQAWithSourcesChain.html)\n\n```text\n {\'question\': \'What are the approaches to Task Decomposition?\',\n \'answer\': \'The approaches to Task Decomposition include:\\n1. Using LLM with simple prompting, such as providing steps or subgoals for achieving a task.\\n2. Using task-specific instructions, such as providing a specific instruction like "Write a story outline" for writing a novel.\\n3. Using human inputs to decompose the task.\\nAnother approach is the Tree of Thoughts, which extends the Chain of Thought (CoT) technique by exploring multiple reasoning possibilities at each step and generating multiple thoughts per step, creating a tree structure. The search process can be BFS or DFS, and each state can be evaluated by a classifier or majority vote.\\nSources: https://lilianweng.github.io/posts/2023-06-23-agent/\',\n \'sources\': \'\'}\n```\n\n#### Customizing retrieved document processing\u200b\n\nRetrieved documents can be fed to an LLM for answer distillation in a few different ways.\n\n`stuff`, `refine`, `map-reduce`, and `map-rerank` chains for passing documents to an LLM prompt are well summarized [here](/docs/modules/chains/document/).\n\n`stuff` is commonly used because it simply "stuffs" all retrieved documents into the prompt.\n\nThe [load_qa_chain](/docs/use_cases/question_answering/how_to/question_answering.html) is an easy way to pass documents to an LLM using these various approaches (e.g., see `chain_type`).\n\n```python\nfrom langchain.chains.question_answering import load_qa_chain\n\nchain = load_qa_chain(llm, chain_type="stuff")\nchain({"input_documents": unique_docs, "question": question},return_only_outputs=True)\n```\n\n> **API Reference:**\n> - [load_qa_chain](https://api.python.langchain.com/en/latest/chains/langchain.chains.question_answering.load_qa_chain.html)\n\n```text\n {\'output_text\': \'The approaches to task decomposition mentioned in the provided context are:\\n\\n1. Chain of thought (CoT): This approach involves instructing the language model to "think step by step" and decompose complex tasks into smaller and simpler steps. It enhances model performance on complex tasks by utilizing more test-time computation.\\n\\n2. Tree of Thoughts: This approach extends CoT by exploring multiple reasoning possibilities at each step. It decomposes the problem into multiple thought steps and generates multiple thoughts per step, creating a tree structure. The search process can be BFS or DFS, and each state is evaluated by a classifier or majority vote.\\n\\n3. LLM with simple prompting: This approach involves using a language model with simple prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?" to perform task decomposition.\\n\\n4. Task-specific instructions: This approach involves providing task-specific instructions to guide the language model in decomposing the task. For example, providing the instruction "Write a story outline" for the task of writing a novel.\\n\\n5. Human inputs: Task decomposition can also be done with human inputs, where humans provide guidance and input to break down the task into smaller subtasks.\'}\n```\n\nWe can also pass the `chain_type` to `RetrievalQA`.\n\n```python\nqa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever(),\n chain_type="stuff")\nresult = qa_chain({"query": question})\n```\n\nIn summary, the user can choose the desired level of abstraction for QA:\n\n\n\n## Step 6. Chat\u200b\n\nSee our [use-case on chat](/docs/use_cases/chatbots) for detail on this!', metadata={'source': 'https://python.langchain.com/docs/use_cases/question_answering/', 'title': 'Question Answering | 🦜️🔗 Langchain', 'description': 'Open In Collab', 'language': 'en'}),
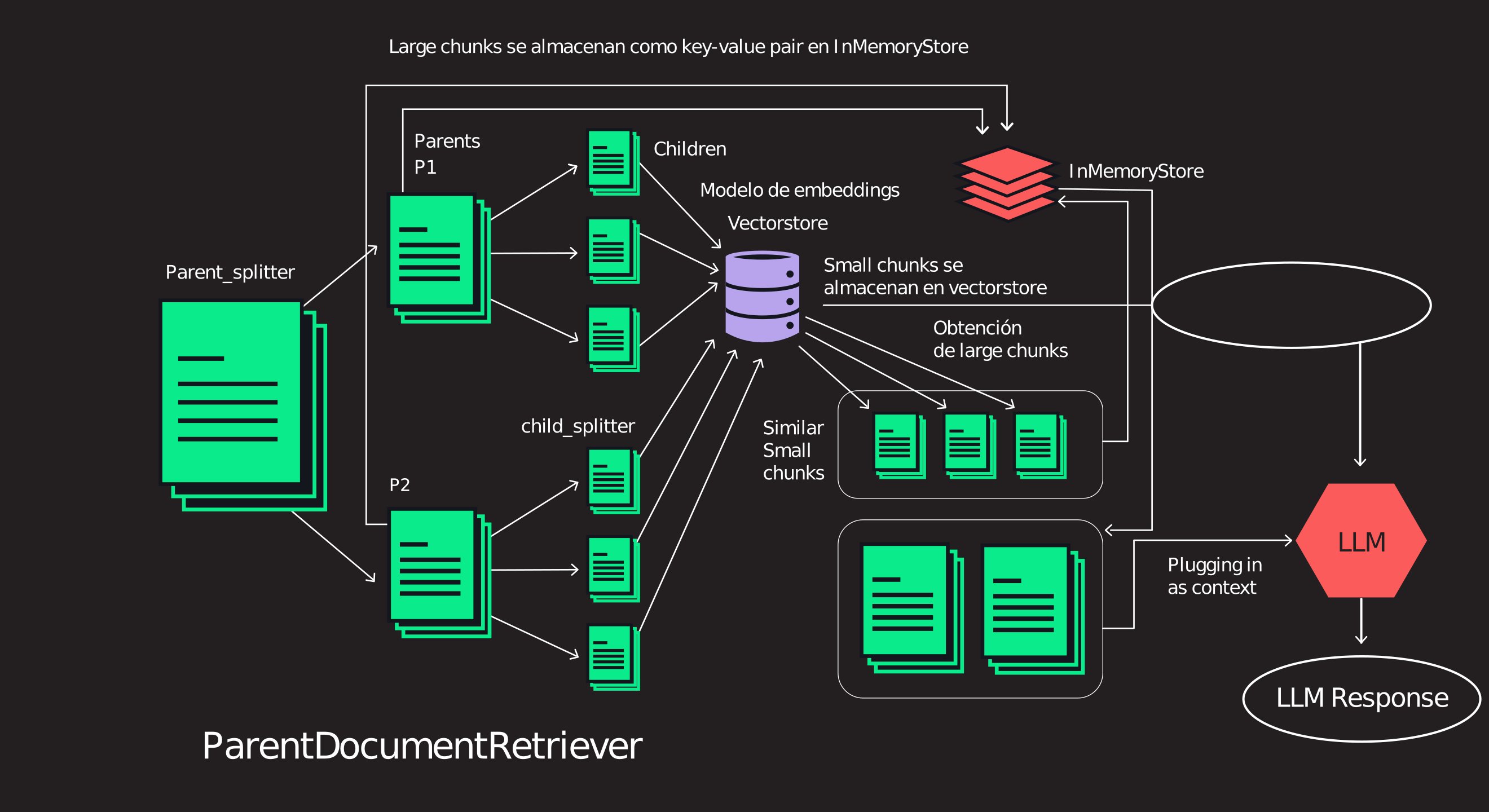
Document(page_content="# Retrieval\n\nMany LLM applications require user-specific data that is not part of the model's training set.\nThe primary way of accomplishing this is through Retrieval Augmented Generation (RAG).\nIn this process, external data is _retrieved_ and then passed to the LLM when doing the _generation_ step.\n\nLangChain provides all the building blocks for RAG applications - from simple to complex.\nThis section of the documentation covers everything related to the _retrieval_ step - e.g. the fetching of the data.\nAlthough this sounds simple, it can be subtly complex.\nThis encompasses several key modules.\n\n\n\n**Document loaders**\n\nLoad documents from many different sources.\nLangChain provides over 100 different document loaders as well as integrations with other major providers in the space,\nlike AirByte and Unstructured.\nWe provide integrations to load all types of documents (HTML, PDF, code) from all types of locations (private s3 buckets, public websites).\n\n**Document transformers**\n\nA key part of retrieval is fetching only the relevant parts of documents.\nThis involves several transformation steps in order to best prepare the documents for retrieval.\nOne of the primary ones here is splitting (or chunking) a large document into smaller chunks.\nLangChain provides several different algorithms for doing this, as well as logic optimized for specific document types (code, markdown, etc).\n\n**Text embedding models**\n\nAnother key part of retrieval has become creating embeddings for documents.\nEmbeddings capture the semantic meaning of the text, allowing you to quickly and\nefficiently find other pieces of text that are similar.\nLangChain provides integrations with over 25 different embedding providers and methods,\nfrom open-source to proprietary API,\nallowing you to choose the one best suited for your needs.\nLangChain provides a standard interface, allowing you to easily swap between models.\n\n**Vector stores**\n\nWith the rise of embeddings, there has emerged a need for databases to support efficient storage and searching of these embeddings.\nLangChain provides integrations with over 50 different vectorstores, from open-source local ones to cloud-hosted proprietary ones,\nallowing you to choose the one best suited for your needs.\nLangChain exposes a standard interface, allowing you to easily swap between vector stores.\n\n**Retrievers**\n\nOnce the data is in the database, you still need to retrieve it.\nLangChain supports many different retrieval algorithms and is one of the places where we add the most value.\nWe support basic methods that are easy to get started - namely simple semantic search.\nHowever, we have also added a collection of algorithms on top of this to increase performance.\nThese include:\n\n- [Parent Document Retriever](/docs/modules/data_connection/retrievers/parent_document_retriever): This allows you to create multiple embeddings per parent document, allowing you to look up smaller chunks but return larger context.\n- [Self Query Retriever](/docs/modules/data_connection/retrievers/self_query): User questions often contain a reference to something that isn't just semantic but rather expresses some logic that can best be represented as a metadata filter. Self-query allows you to parse out the _semantic_ part of a query from other _metadata filters_ present in the query.\n- [Ensemble Retriever](/docs/modules/data_connection/retrievers/ensemble): Sometimes you may want to retrieve documents from multiple different sources, or using multiple different algorithms. The ensemble retriever allows you to easily do this.\n- And more!", metadata={'source': 'https://python.langchain.com/docs/modules/data_connection/', 'title': 'Retrieval | 🦜️🔗 Langchain', 'description': "Many LLM applications require user-specific data that is not part of the model's training set.", 'language': 'en'})]