from functools import partial
import pandas as pd
import seaborn as sns
import tiktoken
from langchain.schema import Document
from langchain.text_splitter import (
Language,
MarkdownHeaderTextSplitter,
RecursiveCharacterTextSplitter,
)
from src.langchain_docs_loader import LangchainDocsLoaderFragmentación de texto con base en el contexto
Una vez que se ha extraído el texto de un documento, es posible que se requiera dividirlo en fragmentos más pequeños, como oraciones o palabras, para su posterior análisis. En este notebook se presentan algunas técnicas para realizar esta tarea con base en el contexto.
Librerías
Utilizaremos la función print_example_doc_splits_from_docs a través de este notebook para imprimir el contenido de los documentos cuya metadata source coincida con el valor proporcionado.
def print_example_doc_splits_from_docs(
docs: list[Document],
source: str,
) -> None:
for doc in docs:
if doc.metadata["source"] == source:
print("\n")
print(f" {doc.metadata['source']} ".center(80, "="))
print("\n")
print(doc.page_content)
print_split_for_lcle = partial(
print_example_doc_splits_from_docs,
source="https://python.langchain.com/docs/expression_language/interface",
)Carga de datos
De aquí en adelante, utilizaremos el conjunto de documentos extraídos en el notebook 01_context_aware_text_extraction.ipynb.
loader = LangchainDocsLoader(include_output_cells=True)
docs = loader.load()
f"Loaded {len(docs)} documents"'Loaded 962 documents'Fragmentación de texto sin tener en cuenta el contexto
La forma más sencilla de fragmentar texto es utilizando la función split de Python. Esta función recibe como parámetro un caracter o cadena de caracteres que se utilizará como separador. Por ejemplo, para fragmentar un texto en oraciones, se puede utilizar el caracter . como separador.
Sin embargo, podemos ir un poco más allá y utilizar RecursiveCharacterTextSplitter() de langchain para dividir texto observando caracteres de forma recursiva. Esta herramienta intenta, de manera recursiva, dividir el texto por diferentes caracteres para encontrar uno que funcione, permitiendo así una fragmentación de texto más precisa y adaptable a diferentes contextos y formatos de texto, aunque no tenga en cuenta el contexto semántico del mismo.
text_splitter_without_context = RecursiveCharacterTextSplitter()
splitted_documents_without_context = text_splitter_without_context.split_documents(docs)
print_split_for_lcle(splitted_documents_without_context)
======= https://python.langchain.com/docs/expression_language/interface ========
# Interface
In an effort to make it as easy as possible to create custom chains, we've implemented a ["Runnable"](https://api.python.langchain.com/en/latest/schema/langchain.schema.runnable.Runnable.html#langchain.schema.runnable.Runnable) protocol that most components implement. This is a standard interface with a few different methods, which makes it easy to define custom chains as well as making it possible to invoke them in a standard way. The standard interface exposed includes:
- `stream`: stream back chunks of the response
- `invoke`: call the chain on an input
- `batch`: call the chain on a list of inputs
These also have corresponding async methods:
- `astream`: stream back chunks of the response async
- `ainvoke`: call the chain on an input async
- `abatch`: call the chain on a list of inputs async
The type of the input varies by component:
| Component | Input Type |
| ---- | ---- |
| Prompt | Dictionary |
| Retriever | Single string |
| Model | Single string, list of chat messages or a PromptValue |
The output type also varies by component:
| Component | Output Type |
| ---- | ---- |
| LLM | String |
| ChatModel | ChatMessage |
| Prompt | PromptValue |
| Retriever | List of documents |
Let's take a look at these methods! To do so, we'll create a super simple PromptTemplate + ChatModel chain.
```python
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
```
> **API Reference:**
> - [ChatPromptTemplate](https://api.python.langchain.com/en/latest/prompts/langchain.prompts.chat.ChatPromptTemplate.html)
> - [ChatOpenAI](https://api.python.langchain.com/en/latest/chat_models/langchain.chat_models.openai.ChatOpenAI.html)
```python
model = ChatOpenAI()
```
```python
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
```
```python
chain = prompt | model
```
## Stream
```python
for s in chain.stream({"topic": "bears"}):
print(s.content, end="", flush=True)
```
```text
Sure, here's a bear-themed joke for you:
Why don't bears wear shoes?
Because they have bear feet!
```
## Invoke
```python
chain.invoke({"topic": "bears"})
```
```text
AIMessage(content="Why don't bears wear shoes?\n\nBecause they already have bear feet!", additional_kwargs={}, example=False)
```
## Batch
```python
chain.batch([{"topic": "bears"}, {"topic": "cats"}])
```
```text
[AIMessage(content="Why don't bears ever wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
AIMessage(content="Why don't cats play poker in the wild?\n\nToo many cheetahs!", additional_kwargs={}, example=False)]
```
You can set the number of concurrent requests by using the `max_concurrency` parameter
```python
chain.batch([{"topic": "bears"}, {"topic": "cats"}], config={"max_concurrency": 5})
```
```text
[AIMessage(content="Why don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
AIMessage(content="Why don't cats play poker in the wild?\n\nToo many cheetahs!", additional_kwargs={}, example=False)]
```
## Async Stream
```python
async for s in chain.astream({"topic": "bears"}):
print(s.content, end="", flush=True)
```
```text
Why don't bears wear shoes?
Because they have bear feet!
```
## Async Invoke
```python
await chain.ainvoke({"topic": "bears"})
```
```text
AIMessage(content="Sure, here you go:\n\nWhy don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False)
```
## Async Batch
```python
await chain.abatch([{"topic": "bears"}])
```
```text
[AIMessage(content="Why don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False)]
```
## Parallelism
Let's take a look at how LangChain Expression Language support parralel requests as much as possible. For example, when using a RunnableMapping (often written as a dictionary) it executes each element in parralel.
======= https://python.langchain.com/docs/expression_language/interface ========
```python
from langchain.schema.runnable import RunnableMap
chain1 = ChatPromptTemplate.from_template("tell me a joke about {topic}") | model
chain2 = ChatPromptTemplate.from_template("write a short (2 line) poem about {topic}") | model
combined = RunnableMap({
"joke": chain1,
"poem": chain2,
})
```
> **API Reference:**
> - [RunnableMap](https://api.python.langchain.com/en/latest/schema/langchain.schema.runnable.base.RunnableMap.html)
```python
chain1.invoke({"topic": "bears"})
```
```text
CPU times: user 31.7 ms, sys: 8.59 ms, total: 40.3 ms
Wall time: 1.05 s
AIMessage(content="Why don't bears like fast food?\n\nBecause they can't catch it!", additional_kwargs={}, example=False)
```
```python
chain2.invoke({"topic": "bears"})
```
```text
CPU times: user 42.9 ms, sys: 10.2 ms, total: 53 ms
Wall time: 1.93 s
AIMessage(content="In forest's embrace, bears roam free,\nSilent strength, nature's majesty.", additional_kwargs={}, example=False)
```
```python
combined.invoke({"topic": "bears"})
```
```text
CPU times: user 96.3 ms, sys: 20.4 ms, total: 117 ms
Wall time: 1.1 s
{'joke': AIMessage(content="Why don't bears wear socks?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
'poem': AIMessage(content="In forest's embrace,\nMajestic bears leave their trace.", additional_kwargs={}, example=False)}
```Fragmentación de texto con contexto de distrubución de tokens
En muchas ocasiones, el contexto de cómo se distribuyen los tokens o caracteres en el texto puede ser de gran ayuda para decidir cómo fragmentar el texto. Veámoslo con un ejemplo.
Funciones de apoyo
def num_tokens_from_string(string: str, encoding_name: str = "cl100k_base") -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
def num_tokens_from_document(
document: Document, encoding_name: str = "cl100k_base"
) -> int:
"""Returns the number of tokens in a document."""
return num_tokens_from_string(document.page_content, encoding_name)Estadísticas de tokens en los textos
Calculemos algunas estadísticas de los tokens en los textos utilizando pandas.
tokens_per_document = pd.Series([num_tokens_from_document(doc) for doc in docs])
tokens_per_document.describe()count 962.000000
mean 1599.195426
std 3419.855171
min 42.000000
25% 382.250000
50% 809.500000
75% 1646.750000
max 80983.000000
dtype: float64La amplia variabilidad en el número de tokens por documento sugiere que se está tratando con documentos de longitudes muy diversas, desde muy cortos hasta muy largos. Esto podría afectar a los análisis subsiguientes y debería tenerse en cuenta al desarrollar modelos de procesamiento de lenguaje natural, ajustando posiblemente los métodos de preprocesamiento o utilizando técnicas que puedan manejar eficientemente documentos de diferentes longitudes. Además, el sesgo a la derecha en la distribución sugiere que, aunque la mayoría de los documentos son relativamente cortos, hay algunos documentos extremadamente largos que podrían ser atípicos y necesitar un tratamiento especial.
Visualización de distribución de tokens sin outliers
# Calculate Q1, Q3, and IQR
Q1 = tokens_per_document.quantile(0.25)
Q3 = tokens_per_document.quantile(0.75)
IQR = Q3 - Q1
upper_bound = Q3 + 1.5 * IQR
# We only filter outliers by upper bound since we don't have problems with short documents.
filtered_tokens = tokens_per_document[(tokens_per_document <= upper_bound)]
# Plot the important sections of the histogram
sns.set_theme(style="whitegrid")
fig = sns.histplot(filtered_tokens, kde=True)
fig.set(
xlabel="Number of tokens",
ylabel="Number of documents",
title="Number of tokens per document",
)[Text(0.5, 0, 'Number of tokens'),
Text(0, 0.5, 'Number of documents'),
Text(0.5, 1.0, 'Number of tokens per document')]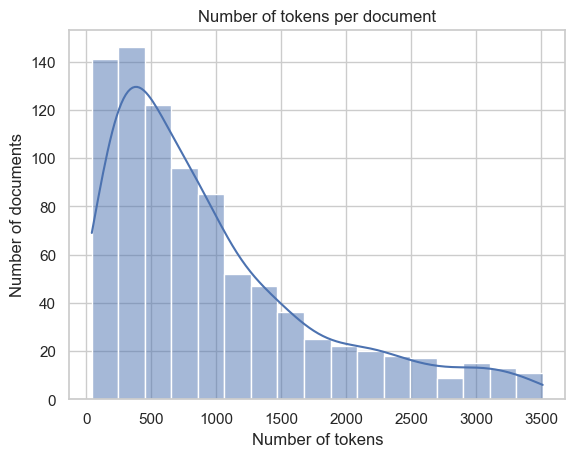
Fragmentación de texto con base en la distribución de tokens
Considerando los resultados anteriores, podemos utilizar la información de la distribución de tokens para fragmentar el texto de forma más precisa. Para ello, utilizaremos la función RecursiveCharacterTextSplitter() de langchain, pero ahora especificaremos los parámetros chunk_size y chunk_overlap.
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=50,
length_function=num_tokens_from_string,
)
splitted_with_little_context = splitter.split_documents(docs)
print_split_for_lcle(splitted_with_little_context)
======= https://python.langchain.com/docs/expression_language/interface ========
# Interface
In an effort to make it as easy as possible to create custom chains, we've implemented a ["Runnable"](https://api.python.langchain.com/en/latest/schema/langchain.schema.runnable.Runnable.html#langchain.schema.runnable.Runnable) protocol that most components implement. This is a standard interface with a few different methods, which makes it easy to define custom chains as well as making it possible to invoke them in a standard way. The standard interface exposed includes:
- `stream`: stream back chunks of the response
- `invoke`: call the chain on an input
- `batch`: call the chain on a list of inputs
These also have corresponding async methods:
- `astream`: stream back chunks of the response async
- `ainvoke`: call the chain on an input async
- `abatch`: call the chain on a list of inputs async
The type of the input varies by component:
| Component | Input Type |
| ---- | ---- |
| Prompt | Dictionary |
| Retriever | Single string |
| Model | Single string, list of chat messages or a PromptValue |
The output type also varies by component:
| Component | Output Type |
| ---- | ---- |
| LLM | String |
| ChatModel | ChatMessage |
| Prompt | PromptValue |
| Retriever | List of documents |
Let's take a look at these methods! To do so, we'll create a super simple PromptTemplate + ChatModel chain.
```python
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
```
> **API Reference:**
> - [ChatPromptTemplate](https://api.python.langchain.com/en/latest/prompts/langchain.prompts.chat.ChatPromptTemplate.html)
> - [ChatOpenAI](https://api.python.langchain.com/en/latest/chat_models/langchain.chat_models.openai.ChatOpenAI.html)
```python
model = ChatOpenAI()
```
```python
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
```
```python
chain = prompt | model
```
## Stream
```python
for s in chain.stream({"topic": "bears"}):
print(s.content, end="", flush=True)
```
```text
Sure, here's a bear-themed joke for you:
Why don't bears wear shoes?
Because they have bear feet!
```
## Invoke
```python
chain.invoke({"topic": "bears"})
```
```text
AIMessage(content="Why don't bears wear shoes?\n\nBecause they already have bear feet!", additional_kwargs={}, example=False)
```
## Batch
```python
chain.batch([{"topic": "bears"}, {"topic": "cats"}])
```
```text
[AIMessage(content="Why don't bears ever wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
AIMessage(content="Why don't cats play poker in the wild?\n\nToo many cheetahs!", additional_kwargs={}, example=False)]
```
You can set the number of concurrent requests by using the `max_concurrency` parameter
```python
chain.batch([{"topic": "bears"}, {"topic": "cats"}], config={"max_concurrency": 5})
```
```text
[AIMessage(content="Why don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
AIMessage(content="Why don't cats play poker in the wild?\n\nToo many cheetahs!", additional_kwargs={}, example=False)]
```
## Async Stream
```python
async for s in chain.astream({"topic": "bears"}):
print(s.content, end="", flush=True)
```
```text
Why don't bears wear shoes?
Because they have bear feet!
```
## Async Invoke
```python
await chain.ainvoke({"topic": "bears"})
```
```text
AIMessage(content="Sure, here you go:\n\nWhy don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False)
```
## Async Batch
```python
await chain.abatch([{"topic": "bears"}])
```
```text
[AIMessage(content="Why don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False)]
```
## Parallelism
Let's take a look at how LangChain Expression Language support parralel requests as much as possible. For example, when using a RunnableMapping (often written as a dictionary) it executes each element in parralel.
======= https://python.langchain.com/docs/expression_language/interface ========
Let's take a look at how LangChain Expression Language support parralel requests as much as possible. For example, when using a RunnableMapping (often written as a dictionary) it executes each element in parralel.
```python
from langchain.schema.runnable import RunnableMap
chain1 = ChatPromptTemplate.from_template("tell me a joke about {topic}") | model
chain2 = ChatPromptTemplate.from_template("write a short (2 line) poem about {topic}") | model
combined = RunnableMap({
"joke": chain1,
"poem": chain2,
})
```
> **API Reference:**
> - [RunnableMap](https://api.python.langchain.com/en/latest/schema/langchain.schema.runnable.base.RunnableMap.html)
```python
chain1.invoke({"topic": "bears"})
```
```text
CPU times: user 31.7 ms, sys: 8.59 ms, total: 40.3 ms
Wall time: 1.05 s
AIMessage(content="Why don't bears like fast food?\n\nBecause they can't catch it!", additional_kwargs={}, example=False)
```
```python
chain2.invoke({"topic": "bears"})
```
```text
CPU times: user 42.9 ms, sys: 10.2 ms, total: 53 ms
Wall time: 1.93 s
AIMessage(content="In forest's embrace, bears roam free,\nSilent strength, nature's majesty.", additional_kwargs={}, example=False)
```
```python
combined.invoke({"topic": "bears"})
```
```text
CPU times: user 96.3 ms, sys: 20.4 ms, total: 117 ms
Wall time: 1.1 s
{'joke': AIMessage(content="Why don't bears wear socks?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
'poem': AIMessage(content="In forest's embrace,\nMajestic bears leave their trace.", additional_kwargs={}, example=False)}
```Fragmentación de texto con contexto
Con el dominio del problema podemos fragmentar el texto de manera más precisa.
Fragmentación de texto con base en una especificación de lenguaje como contexto
En nuestro ejemplo, nuestros documentos son Markdown, por lo que podríamos fragmentar el documento en función de los caracteres que se utilizan para definir los encabezados de las secciones y otros elementos de formato.
En este caso, la función internamente utiliza los siguientes patrones para fragmentar el texto:
[
# First, try to split along Markdown headings (starting with level 2)
"\n#{1,6} ",
# Note the alternative syntax for headings (below) is not handled here
# Heading level 2
# ---------------
# End of code block
"```\n",
# Horizontal lines
"\n\\*\\*\\*+\n",
"\n---+\n",
"\n___+\n",
# Note that this splitter doesn't handle horizontal lines defined
# by *three or more* of ***, ---, or ___, but this is not handled
"\n\n",
"\n",
" ",
"",
]md_language_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN,
chunk_size=1000,
chunk_overlap=50,
length_function=num_tokens_from_string,
)
md_language_splits = md_language_splitter.split_documents(docs)
print_split_for_lcle(md_language_splits)
======= https://python.langchain.com/docs/expression_language/interface ========
# Interface
In an effort to make it as easy as possible to create custom chains, we've implemented a ["Runnable"](https://api.python.langchain.com/en/latest/schema/langchain.schema.runnable.Runnable.html#langchain.schema.runnable.Runnable) protocol that most components implement. This is a standard interface with a few different methods, which makes it easy to define custom chains as well as making it possible to invoke them in a standard way. The standard interface exposed includes:
- `stream`: stream back chunks of the response
- `invoke`: call the chain on an input
- `batch`: call the chain on a list of inputs
These also have corresponding async methods:
- `astream`: stream back chunks of the response async
- `ainvoke`: call the chain on an input async
- `abatch`: call the chain on a list of inputs async
The type of the input varies by component:
| Component | Input Type |
| ---- | ---- |
| Prompt | Dictionary |
| Retriever | Single string |
| Model | Single string, list of chat messages or a PromptValue |
The output type also varies by component:
| Component | Output Type |
| ---- | ---- |
| LLM | String |
| ChatModel | ChatMessage |
| Prompt | PromptValue |
| Retriever | List of documents |
Let's take a look at these methods! To do so, we'll create a super simple PromptTemplate + ChatModel chain.
```python
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
```
> **API Reference:**
> - [ChatPromptTemplate](https://api.python.langchain.com/en/latest/prompts/langchain.prompts.chat.ChatPromptTemplate.html)
> - [ChatOpenAI](https://api.python.langchain.com/en/latest/chat_models/langchain.chat_models.openai.ChatOpenAI.html)
```python
model = ChatOpenAI()
```
```python
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
```
```python
chain = prompt | model
```
## Stream
```python
for s in chain.stream({"topic": "bears"}):
print(s.content, end="", flush=True)
```
```text
Sure, here's a bear-themed joke for you:
Why don't bears wear shoes?
Because they have bear feet!
```
## Invoke
```python
chain.invoke({"topic": "bears"})
```
```text
AIMessage(content="Why don't bears wear shoes?\n\nBecause they already have bear feet!", additional_kwargs={}, example=False)
```
## Batch
```python
chain.batch([{"topic": "bears"}, {"topic": "cats"}])
```
```text
[AIMessage(content="Why don't bears ever wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
AIMessage(content="Why don't cats play poker in the wild?\n\nToo many cheetahs!", additional_kwargs={}, example=False)]
```
You can set the number of concurrent requests by using the `max_concurrency` parameter
```python
chain.batch([{"topic": "bears"}, {"topic": "cats"}], config={"max_concurrency": 5})
```
```text
[AIMessage(content="Why don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
AIMessage(content="Why don't cats play poker in the wild?\n\nToo many cheetahs!", additional_kwargs={}, example=False)]
```
## Async Stream
```python
async for s in chain.astream({"topic": "bears"}):
print(s.content, end="", flush=True)
```
```text
Why don't bears wear shoes?
Because they have bear feet!
```
## Async Invoke
```python
await chain.ainvoke({"topic": "bears"})
```
```text
AIMessage(content="Sure, here you go:\n\nWhy don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False)
```
## Async Batch
```python
await chain.abatch([{"topic": "bears"}])
```
```text
[AIMessage(content="Why don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False)]
```
======= https://python.langchain.com/docs/expression_language/interface ========
## Parallelism
Let's take a look at how LangChain Expression Language support parralel requests as much as possible. For example, when using a RunnableMapping (often written as a dictionary) it executes each element in parralel.
```python
from langchain.schema.runnable import RunnableMap
chain1 = ChatPromptTemplate.from_template("tell me a joke about {topic}") | model
chain2 = ChatPromptTemplate.from_template("write a short (2 line) poem about {topic}") | model
combined = RunnableMap({
"joke": chain1,
"poem": chain2,
})
```
> **API Reference:**
> - [RunnableMap](https://api.python.langchain.com/en/latest/schema/langchain.schema.runnable.base.RunnableMap.html)
```python
chain1.invoke({"topic": "bears"})
```
```text
CPU times: user 31.7 ms, sys: 8.59 ms, total: 40.3 ms
Wall time: 1.05 s
AIMessage(content="Why don't bears like fast food?\n\nBecause they can't catch it!", additional_kwargs={}, example=False)
```
```python
chain2.invoke({"topic": "bears"})
```
```text
CPU times: user 42.9 ms, sys: 10.2 ms, total: 53 ms
Wall time: 1.93 s
AIMessage(content="In forest's embrace, bears roam free,\nSilent strength, nature's majesty.", additional_kwargs={}, example=False)
```
```python
combined.invoke({"topic": "bears"})
```
```text
CPU times: user 96.3 ms, sys: 20.4 ms, total: 117 ms
Wall time: 1.1 s
{'joke': AIMessage(content="Why don't bears wear socks?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
'poem': AIMessage(content="In forest's embrace,\nMajestic bears leave their trace.", additional_kwargs={}, example=False)}
```Fragmentación de texto utilizando encabezados como contexto
En contraste con el ejemplo anterior, en este caso utilizaremos únicamente los encabezados de los documentos como contexto para fragmentar el texto. Estos encabezados pasarán a formar parte de los meta-datos de los fragmentos.
Dentro de cada fragmento de encabezado, podríamos repetir el proceso de fragmentación de texto con base en la distribución de tokens o en una especificación de lenguaje como contexto.
md_headers_splits: list[Document] = []
for doc in docs:
md_header_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=[
("#", "Header 1"),
("##", "Header 2"),
]
)
text_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN,
chunk_size=1000, # try then with 150
chunk_overlap=50,
length_function=num_tokens_from_string,
)
splits = md_header_splitter.split_text(doc.page_content)
splits = text_splitter.split_documents(splits)
splits = [
Document(
page_content=split.page_content,
metadata={
**split.metadata,
**doc.metadata,
},
)
for split in splits
]
md_headers_splits.extend(splits)
print_split_for_lcle(md_headers_splits)
======= https://python.langchain.com/docs/expression_language/interface ========
In an effort to make it as easy as possible to create custom chains, we've implemented a ["Runnable"](https://api.python.langchain.com/en/latest/schema/langchain.schema.runnable.Runnable.html#langchain.schema.runnable.Runnable) protocol that most components implement. This is a standard interface with a few different methods, which makes it easy to define custom chains as well as making it possible to invoke them in a standard way. The standard interface exposed includes:
- `stream`: stream back chunks of the response
- `invoke`: call the chain on an input
- `batch`: call the chain on a list of inputs
These also have corresponding async methods:
- `astream`: stream back chunks of the response async
- `ainvoke`: call the chain on an input async
- `abatch`: call the chain on a list of inputs async
The type of the input varies by component:
| Component | Input Type |
| ---- | ---- |
| Prompt | Dictionary |
| Retriever | Single string |
| Model | Single string, list of chat messages or a PromptValue |
The output type also varies by component:
| Component | Output Type |
| ---- | ---- |
| LLM | String |
| ChatModel | ChatMessage |
| Prompt | PromptValue |
| Retriever | List of documents |
Let's take a look at these methods! To do so, we'll create a super simple PromptTemplate + ChatModel chain.
```python
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
```
> **API Reference:**
> - [ChatPromptTemplate](https://api.python.langchain.com/en/latest/prompts/langchain.prompts.chat.ChatPromptTemplate.html)
> - [ChatOpenAI](https://api.python.langchain.com/en/latest/chat_models/langchain.chat_models.openai.ChatOpenAI.html)
```python
model = ChatOpenAI()
```
```python
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
```
```python
chain = prompt | model
```
======= https://python.langchain.com/docs/expression_language/interface ========
```python
for s in chain.stream({"topic": "bears"}):
print(s.content, end="", flush=True)
```
```text
Sure, here's a bear-themed joke for you:
Why don't bears wear shoes?
Because they have bear feet!
```
======= https://python.langchain.com/docs/expression_language/interface ========
```python
chain.invoke({"topic": "bears"})
```
```text
AIMessage(content="Why don't bears wear shoes?\n\nBecause they already have bear feet!", additional_kwargs={}, example=False)
```
======= https://python.langchain.com/docs/expression_language/interface ========
```python
chain.batch([{"topic": "bears"}, {"topic": "cats"}])
```
```text
[AIMessage(content="Why don't bears ever wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
AIMessage(content="Why don't cats play poker in the wild?\n\nToo many cheetahs!", additional_kwargs={}, example=False)]
```
You can set the number of concurrent requests by using the `max_concurrency` parameter
```python
chain.batch([{"topic": "bears"}, {"topic": "cats"}], config={"max_concurrency": 5})
```
```text
[AIMessage(content="Why don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
AIMessage(content="Why don't cats play poker in the wild?\n\nToo many cheetahs!", additional_kwargs={}, example=False)]
```
======= https://python.langchain.com/docs/expression_language/interface ========
```python
async for s in chain.astream({"topic": "bears"}):
print(s.content, end="", flush=True)
```
```text
Why don't bears wear shoes?
Because they have bear feet!
```
======= https://python.langchain.com/docs/expression_language/interface ========
```python
await chain.ainvoke({"topic": "bears"})
```
```text
AIMessage(content="Sure, here you go:\n\nWhy don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False)
```
======= https://python.langchain.com/docs/expression_language/interface ========
```python
await chain.abatch([{"topic": "bears"}])
```
```text
[AIMessage(content="Why don't bears wear shoes?\n\nBecause they have bear feet!", additional_kwargs={}, example=False)]
```
======= https://python.langchain.com/docs/expression_language/interface ========
Let's take a look at how LangChain Expression Language support parralel requests as much as possible. For example, when using a RunnableMapping (often written as a dictionary) it executes each element in parralel.
```python
from langchain.schema.runnable import RunnableMap
chain1 = ChatPromptTemplate.from_template("tell me a joke about {topic}") | model
chain2 = ChatPromptTemplate.from_template("write a short (2 line) poem about {topic}") | model
combined = RunnableMap({
"joke": chain1,
"poem": chain2,
})
```
> **API Reference:**
> - [RunnableMap](https://api.python.langchain.com/en/latest/schema/langchain.schema.runnable.base.RunnableMap.html)
```python
chain1.invoke({"topic": "bears"})
```
```text
CPU times: user 31.7 ms, sys: 8.59 ms, total: 40.3 ms
Wall time: 1.05 s
AIMessage(content="Why don't bears like fast food?\n\nBecause they can't catch it!", additional_kwargs={}, example=False)
```
```python
chain2.invoke({"topic": "bears"})
```
```text
CPU times: user 42.9 ms, sys: 10.2 ms, total: 53 ms
Wall time: 1.93 s
AIMessage(content="In forest's embrace, bears roam free,\nSilent strength, nature's majesty.", additional_kwargs={}, example=False)
```
```python
combined.invoke({"topic": "bears"})
```
```text
CPU times: user 96.3 ms, sys: 20.4 ms, total: 117 ms
Wall time: 1.1 s
{'joke': AIMessage(content="Why don't bears wear socks?\n\nBecause they have bear feet!", additional_kwargs={}, example=False),
'poem': AIMessage(content="In forest's embrace,\nMajestic bears leave their trace.", additional_kwargs={}, example=False)}
```